AI による個人情報の識別と分析改善
November 22, 2024

はじめに
現代の企業は、膨大なデータを効率的に管理しながら個人情報を保護するという重要な課題に直面しています。データ量が増加し、その内容が複雑化する中で、個人情報を正確に特定し管理することは一層困難になっています。この課題を解決するには、企業が迅速かつ正確にデータを分析できるソリューションを導入することが不可欠です。それにより、データ保護のレベルをさらに向上させることが可能となります。
課題の定義
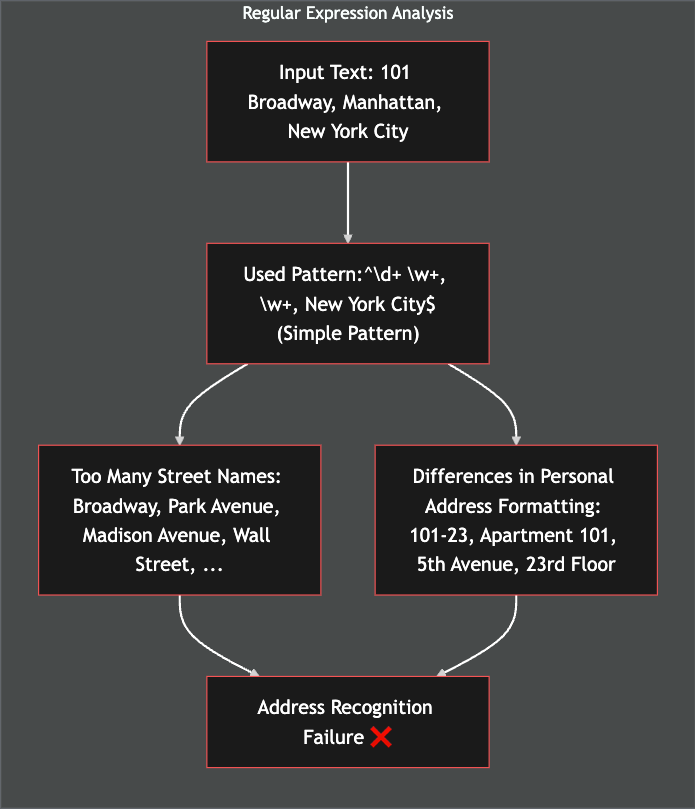
大規模なデータベースにおける個人情報の正確な分類は、多くの企業が直面している重要な課題の一つです。従来の正規表現に基づく固定パターン技術にはいくつかの限界があり、その効果が薄れつつあります。
- データパターンの多様性
- 住所や氏名、医療情報などは標準化された形式がなく、多様な形で表現されることが一般的です。
- 例えば、住所は「110-2430」や「110棟2430号」のように異なる形式で記録されることがあり、医療情報も略語や専門用語を含むさまざまな形式で記録されます。
- 規制遵守の複雑さ
GDPR(一般データ保護規則)、CCPA(カリフォルニア州消費者プライバシー法)、HIPAA(医療保険の携行性と責任に関する法律)、ISO/IEC 27701など、さまざまなグローバルな個人情報保護規制は、企業に対して個人情報を正確に特定し、保護することを求めています。これらの規制に違反すると、法的な問題や罰金、またはお客様からの信頼低下といったリスクが生じます。
- GDPR(一般データ保護規則):欧州連合の個人情報保護規制で、データ主体の権利保障およびデータ処理の透明性を求めます。
- CCPA(カリフォルニア州消費者プライバシー法):米国カリフォルニア州の個人情報保護法で、消費者に対しデータ削除請求権やデータ販売拒否権を提供します。
- HIPAA(医療保険の携行性と責任に関する法律):米国の医療情報保護法であり、医療記録のような機密性の高い個人情報の秘密と安全を保証します。
- ISO/IEC 27701:個人情報管理システム(PIMS)に関する国際標準で、企業が個人情報保護フレームワークを構築し規制を遵守することを支援します。
これらの規制はそれぞれ異なる要件を持っており、対応しない場合、企業は法的、財務的、または評判に関わる深刻なリスクに直面することになります。
-
従来の非効率的なソリューション
- 従来の正規表現ベースのソリューションは、固定されたパターンしか認識できず、新しいデータパターンが登場するたびに修正が必要です。
- これにより運用効率が低下し、企業のコストが増加します。
これらの問題は、データ保護レベルの低下や運用コストの増加といった否定的な影響をもたらします。
目標設定
AI Classifier(AIによる自動分類)の目標は、お客様がデータ保護と管理において実質的な利益を得られるよう支援することです。これにより、企業はデータ管理の複雑さを解消し、個人情報保護のレベルを向上させ、規制遵守を効率的に達成できます。主な目標は以下の通りです。
1. 個人情報識別の精度向上
- 文脈分析に基づく自動分類 : 固定されたパターンに依存せず、データを文脈的に理解することで、住所、氏名、医療情報など多様な個人情報タイプを正確に識別します。
- 新しいデータパターンへの適応 : AIモデルは継続的に学習し、従来のソリューションの限界を克服し、新しいデータパターンにも柔軟に対応します。
これにより、お客様は個人情報識別の精度を大幅に向上させ、データ管理におけるエラーや不確実性を最小限に抑えることができます。
2. 運用効率の向上とコスト削減
- リソース削減 : 大規模データ環境でも高性能な分類を通じて、IT、セキュリティ、データ管理チームの負担を軽減します。
- 時間短縮 : 多様な規模や形式のデータを迅速に処理し、反復作業にかかる時間を削減します。
- 運用の安定性 : AI分類器はデータ処理において高い信頼性と一貫性を提供します。これにより、システムが突然中断したりエラーが発生する状況を防ぎ、安定した運用環境を維持できます。
AIによる自動分類を活用することで、企業は個人情報管理の効率を大幅に向上させ、コアビジネスにより多くのリソースを集中投下できます。
3. 規制遵守の支援
- 自動化された規制対応 : GDPR、CCPA、HIPAA、ISMS-P など、さまざまな個人情報保護規制に対応した自動分類を通じて、法的要件を満たします。
- リアルタイムモニタリングとレポート : 規制遵守を証明できる透明なデータ管理およびレポートを提供します。
- 罰金および法的リスクの軽減 : 規制違反による罰金や評判の低下を防ぎ、企業の信頼性を向上させます。
これにより、企業は規制遵守を確保し、法的リスクを最小化しながら、顧客からの信頼を強化することができます。
ソリューション概要
QueryPieのAI Classifierは、文脈分析とパターン認識技術を組み合わせたAIベースのソリューションで、個人情報を正確かつ効率的に分類することができます。これにより、お客様はデータ管理の複雑さを解消し、個人情報保護のレベルを向上させることが可能になります。AI Classifierが提供する主な機能は以下の通りです:
1. 高度なテキスト理解能力
- 双方向の文脈理解技術を活用し、個人情報を含むデータを正確に分析・分類します。
- 名前、住所、医療情報など、さまざまな個人情報タイプに対応し、構造化データだけでなく、非構造化データにおいても高い精度を保証します。
- データの文脈を理解することで、固定されたパターンに依存せず、柔軟に対応します。
2. 信頼できるデータ収集とデータ精製
- 公的機関のデータベースや公共データポータルから、個人情報分類に必要なデータを収集します。
- 収集されたデータは、重複の削除、エラー修正、標準化などの精緻化プロセスを経て、高品質な学習データとして活用されます。
- 精緻化されたデータは、分類精度を向上させる重要な要素となり、お客様の環境に最適化された結果を提供します。
3. 個別カスタマイズされた分類モデルの提供
- 個人情報の種類ごとに最適化されたモデルを提供します。
- 例えば、名前、住所、医療情報それぞれに特化したAIモデルを適用し、高い精度を維持します。
- 多様な業界やデータ環境に適応できるよう、お客様の要件に応じてモデルをカスタマイズします。
- 継続的な学習とアップデートにより、新しいデータパターンにも柔軟に対応します。
4. 効率的なリソース活用
- 精密な事前フィルタリング機能により、不要なテキストを除外し、処理効率を最大化します。
- モデルの不要な呼び出しを最小限に抑え、システムリソースの使用を最適化し、コスト削減を実現します。
技術的説明
モデル選定の背景
個人情報の分類作業に最適な性能を提供するため、さまざまな AI 言語モデルを比較分析した結果、BERT ベースのモデルを採用しました。最近登場した大規模言語モデル(GPTやClaudeなど)と比較した場合、BERTは以下の理由から個人情報の分類作業に特に適しています。:
- 効率的な処理速度
- BERTはリアルタイムの分類作業に必要な速度と性能をバランスよく提供します。
- 大規模データ環境でも安定して動作し、処理遅延を最小限に抑えます。
- 文脈理解と特徴抽出能力
- BERTは入力されたテキストの双方向文脈を分析し、個人情報を正確に分類する強みを持っています。
- 名前、住所、医療情報など、多様な個人情報タイプを扱う際にも高い精度を維持します。
- モデルの組み合わせと最適化
- 個人情報の種類に応じて最適なモデルを選定し適用しています。
- KoElectra: 韓国語データに最適化されたオープンソースモデルで、特定の個人情報(例:医療記録、住所など)で優れた性能を発揮します。
- BERTベースのカスタムモデル: 独自に学習させたBERTモデルは、短いテキストや省略語によって発生する語彙外(Out-of-Vocabulary)問題でも、オープンソースモデルより安定した性能を提供します。
- この組み合わせにより、多様な個人情報タイプにおいて各モデルの長所を最大限活用しています。
- 個人情報の種類に応じて最適なモデルを選定し適用しています。
- 高い精度と柔軟性
- 各モデルの特性を活用し、個人情報分類作業で高精度を記録しています。
- 特に、新しいデータパターンや環境変化にも柔軟に適応できる学習および更新システムを備えており、変化するデータにも対応可能です。
ソリューション構成要素の説明
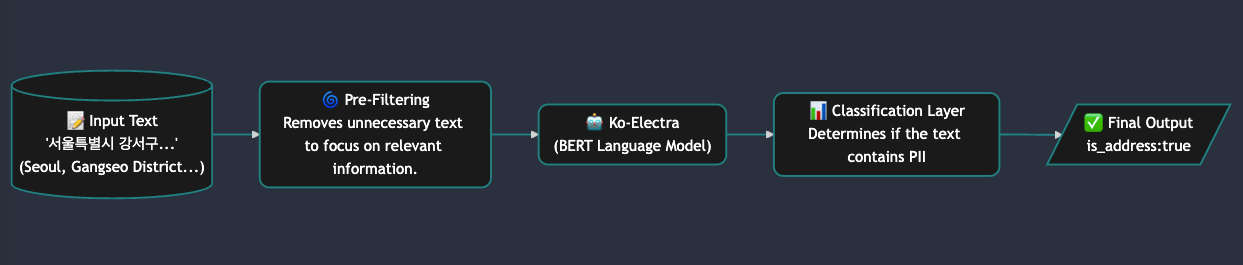
AI Classifierの個人情報分類プロセスは、正確性と効率性を最大化するために段階的に設計されています。以下に、各構成要素の詳細を説明します:
1. 事前フィルタリング
- 役割: 入力された文章を分析し、個人情報に関連しない不要なテキストを除去します。
- 効果: モデルが処理すべきデータ量を削減し、リソースを効率的に使用するとともに処理速度を向上させます。
- 例:
- 特殊文字または数字のみのテキスト: 「123456」「!@#$%^&*」のようなテキストは、住所や医療情報などの個人情報と関連性が低いため、分析段階で除外されます。
- 個人情報タイプと一致しないテキスト: 例えば、「홍길동(ホン・ギルドン)」のようなハングルのみのテキストはローマ字の名前分類プログラムから除外されます。一方、「Gil-Dong Hong」のようなローマ字で構成された名前だけがローマ字分類プログラムに渡されます。
2. 文脈分析モデル
- 役割: Ko-ElectraやBERTベースの言語モデルを活用し、入力テキストの文脈を深く分析します。
- 効果: 単純なキーワード検索ではなく、文脈内の意味を理解することで個人情報の有無を正確に判断します。
- 特徴:
- この段階では住所、名前、医療情報などの複雑なデータタイプにも対応可能です。
- 新しいデータパターンに対しても柔軟に適応します。
3. 分類レイヤー
- 役割: 文脈分析モデルが抽出した特徴ベクトルを基に、テキストが個人情報を含むかどうかを最終的に判定します。
- 効果: 個人情報の有無を正確に判別し、結果を体系的に整理してお客様環境に適した形式で出力します。
- 例(出力形式):
- 入力テキストが住所情報を含む場合、出力結果は
"is_address: true"のような形式で表示されます。 - これにより、個人情報の有無が明確に伝えられるとともに、後続のプロセスで活用できるデータ構造が簡潔化されます。
- 入力テキストが住所情報を含む場合、出力結果は
データ収集および精製

1. データ収集
信頼性の高い公共データおよび検証済みのソースから、個人情報の分類に必要なデータを直接収集します。
- 信頼できるデータソース: 以下のような信頼できる情報源からデータを入手(韓国の場合)。
- 多様なデータタイプ:
- 住所データ: 住所ベース産業支援サービスの韓国語住所データから、市・郡・区の情報を組み合わせ、実際の住所(または類似住所)を生成し、学習に使用します。
- 医療情報: 医療ビッグデータ開放システムの「多頻度傷病別現況」や「多頻度疾病統計」といった統計資料から、医療用語および略語を抽出します。
- 職業および資格情報: 雇用労働部の「韓国職業辞典統合版」、PQI(民間資格情報サービス)などから、職業および資格に関する情報を収集します。
- 正確性の保証: データソースが信頼できる機関であることを確認し、収集段階からデータ品質を厳格に管理します。
2. データ精製
収集したデータはそのままでは使用せず、精製プロセスを通じて一貫性と品質を確保します。
- 重複除去: 同一データが繰り返し学習に使用されないよう、重複項目を削除します。
- エラー修正: 誤った表記や欠落項目を確認し修正します。例えば、住所データの誤字脱字や不適切な構文を修正します。
- 標準化作業: 特殊文字や不要なスペースの削除、略語辞書の構築などを行い、モデルがデータを一貫して処理できるようにします。
- 品質検証: データ精製後、サンプルデータを確認して正確性と適合性を検証します。
分類作業プロセス
1. AI Classifierの学習
AI Classifierは、個人情報の種類ごとの特性を反映したカスタマイズ学習プロセスを通じて高い精度を保証します。
- ファインチューニングプロセス:
- 基本言語モデル(BERTまたはKo-Electra)を個人情報分類作業に合わせてファインチューニングします。
- データの種類ごとに学習を細分化します(例: 名前、住所、医療情報、職業など)。
- データ拡張:
- 様々な形式のデータを含め、モデルが新しいデータパターンに適応できるよう学習します。
- 例:
- "東京都新宿区西新宿2-8-1"
- "東京都新宿区西新宿2丁目8番地1号"
- 上記2つの形式が同一住所であることを認識できるように学習。
- 過学習防止:
- Early stoppingやDropoutなどの技術を活用し、学習データに過度に適応しないようにします。
2. テキスト分類
学習済みのAI Classifierは、リアルタイムで入力データを処理し、個人情報の有無を判断して結果を提供します。
- リアルタイム分析プロセス:
- 入力テキストの文脈を分析し、個人情報の有無を迅速に判断します。
- 例:
- 入力データ:
"東京都新宿区西新宿2-8-1" - 分析結果:
- "住所"として分類。
- 構造化された出力結果:
{ is_address: true, text: "東京都新宿区西新宿2-8-1" }
- 入力データ:
- 分類基準のカスタマイズ:
- お客様のビジネス要件に応じて分類基準を柔軟に設定できる機能を提供します。
- 使用事例: 住所、名前のみを分析対象に設定。
AI Classifier の精度
QueryPieのAI Classifierは、個人情報分類タスクにおいて高い精度を達成するため、徹底したデータ準備と評価プロセスを経ています。ディープラーニングモデルの性能は以下の方法で評価され、継続的に改善されています。
1. データセット構成と評価方法
- 学習用データセット: 個人情報の種類ごとに収集した大規模データを使用してモデルを学習させます。
- テスト データセット: 学習データと明確に分離されたデータを使用してモデル性能を評価します。
- テストデータは実際のデータと似た分布を持ち、さまざまなデータパターンを含むことでモデルの汎化能力を検証します。
- 実世界データの反映:
- 現実の環境では、予期しない新しいデータパターンが登場する可能性があります。
- この問題を克服するため、仮想データ生成やデータ拡張技術を活用して多様なシナリオをモデルに学習させました。
- 例: 「東京都新宿区西新宿2-8-1」と「東京都新宿区西新宿2丁目8番地1号」のように、同一住所を異なる形式で表現したデータを学習。
2. 過学習防止の手法
QueryPieのAI Classifierは過学習を防ぎ、汎化性能を強化するために以下の手法を採用しています。
- 早期停止(Early Stopping)
- 検証データの性能(例: 損失や精度)が一定期間改善されない場合、学習を早期に終了します。
- 例: 検証損失が 5エポック改善されない場合、エポック 15で自動的に学習を終了。
- ドロップアウト(Dropout)
- 学習中に一部のニューロンをランダムに無効化し、特定のニューロンへの依存を減らします。これにより、モデルの多様性を強化します。
- 例: 住所データを学習するネットワークに30%のドロップアウト率を適用し、新しい住所形式への適応力を向上。
- バッチ正規化(Batch Normalization)
- 各層の入力を正規化することで学習速度を向上させ、過学習の可能性を軽減します。
- 例: 職業データを分類するネットワークでバッチ正規化を適用し、初期学習の不安定さを緩和。
- データ拡張(Data Augmentation)
- データの多様性を高めるために、既存のデータを変形して新しい学習データを生成します。
- 例: 住所データ:「ソウル特別市江南区」を「ソウル江南区」に変形したり、ローマ字名で「Ryu」を「Ryoo」に変形したデータを追加し、モデルがさまざまな表現にも対応できるよう学習しました。
3. 精度と性能結果
QueryPieのAI Classifierは、個人情報の種類ごとに最適化されたモデルを使用しており、以下のような高い精度を記録しています。
| 分類項目 | 精度 |
|---|---|
| 韓国人の名前 | 98.9% |
| ローマ字表記の韓国人の名前 | 96.7% |
| 住所 | 99.1% |
| 国コード | 97.8% |
| 職業 | 99.2% |
| 資格情報 | 99.2% |
| 医療情報 | 98.8% |
このような高い精度は、個人情報の種類ごとにBERTモデルをオープンソースまたは独自学習方式で最適化し、各種類に特化した分類レイヤーを個別に学習させることで実現しています。このアプローチを基盤に、今後も過学習を防ぎつつ、性能向上を目指して多様なデータセットを継続的に確保し、学習を進めていく予定です。これにより、お客様は変化するデータ環境の中でも安定した分類性能を体験でき、より正確な個人情報保護サービスを享受することが可能になります。
モデルの最適化およびデプロイ戦略
AI分類システムの高い性能と効率性を維持するため、モデルの最適化とデプロイ方法を体系的に設計しました。これにより、リアルタイム分類環境で安定的かつ迅速な応答が可能になります。
1. モデル最適化戦略
- モデル軽量化:
- BERT系列モデルとKoElectraなどの多様なオープンソースモデルを比較分析し、応答速度と精度の最適なバランスを追求しました。
- これを基にモデルの軽量化作業を実施し、高い性能を維持しつつ処理速度を大幅に改善しました。
- 例: テキスト分類タスクに必要なパラメータ数を最適化し、不要な計算を削減してリソースの使用を最小限に抑えました。
- リアルタイム分類性能の強化:
- 軽量化されたモデルは、リアルタイムでデータを処理するのに最適で、さまざまな規模のデータ環境でも安定した性能を提供します。
- 新しいデータパターンが登場しても迅速に適応できるよう、柔軟な学習構造を設計しています。
2. 効率的なデプロイ戦略
- コンテナベースのデプロイ:
- コンテナ技術を活用し、軽量化された環境で分類モデルを実行します。
- これにより、デプロイプロセスが簡素化され、さまざまなIT環境でも容易に統合および運用が可能です。
- リソース管理および安定性の確保:
- CPUやメモリの使用量を効率的に管理するため、環境変数を利用してリソース使用の上限を設定します。
- 分類タスクが並列で実行される場合でも安定した性能を維持します。
- 例: 大規模データを処理する際にも、応答速度を維持しつつリソースの超過を防止します。
- セキュリティの強化:
- デプロイ環境でマルチステージビルドを利用し、不要なファイルやレイヤーを除去することで軽量化とセキュリティを同時に確保しました。
- 最新のベースイメージを使用し、潜在的なセキュリティ脆弱性を最小化しました。
今後の開発ビジョン
QueryPieのAI Classifierは、グローバル市場で個人情報保護とデータ管理の最適なソリューションとしての地位を確立するため、段階的に拡張を進めています。各国の法的規制や文化的な違いを考慮したローカライズサービスを提供し、さまざまなデータ環境において高い信頼性と性能を保証します。
1. グローバル市場への進出
- ローカライズサービスの提供:
- 各国の個人情報保護法(GDPR、CCPAなど)や規制を詳細に分析し、現地の要件に適合するカスタマイズソリューションを提供します。
- 例: ヨーロッパではGDPR準拠に重点を置いたデータ処理を行い、アメリカではCCPAの削除要求やデータ販売拒否機能を強化しています。
- 言語と文化的差異の反映:
- 多言語対応のモデルを開発し、各言語の特性を反映した精度の高い個人情報分類を実現します。
- 例: 韓国語では「PD」という略語がテレビプロデューサーを指しますが、英語では「Producer」や「Television Producer」と表現されます。これを学習データに反映させています。
- 地域特化型技術の適用:
- 各地域で一般的に使用されるデータ形式や構造を考慮してシステムを最適化しています。
- 例: 日本では住所が「県」から「番地」へと大きな単位から小さな単位の順に書かれますが、ドイツではその順序が逆です。このような国ごとの住所形式の違いを反映した地域特化型分類モデルを適用しています。
2. 性能改善と拡張性強化
- 多言語環境での性能強化:
- 既存の高性能モデルを基に、他言語でも同等の性能を実現できるよう、引き続き最適化を進めます。
- テストおよび検証データセットを拡張し、新しい言語やデータパターンにも安定した性能を保証します。
- データ多様性の拡大:
- 地域別や業種別に特化したデータを統合し、医療、金融、公共機関など、特定分野での利用が可能なソリューションを提供します。
- 例: 医療略語や専門用語が含まれたデータ、または産業別の専門用語や職業情報を追加して学習を行います。
3. お客様中心のサービス提供
- お客様の要件反映:
- 各地域のお客様が直面する特定の課題を把握し、それを解決できるカスタマイズ機能を提供します。
- 例: 特定の規制に準拠するための自動レポート生成機能やリアルタイム警告システムを提供します。
- 一貫したユーザー体験:
- 各地域で同じ品質のサービスを提供し、データ環境が変化してもお客様が信頼できる結果を得られるようサポートします。
終わりに
QueryPieは、個人情報保護の重要な課題を解決するため、高い精度と効率性を兼ね備えたAIベースの分類機能を搭載したAIDD(AI Data Discovery)を開発しました。従来のルールベースの解析システムは、固定されたパターンに依存しており、多様な形式の個人情報を処理する際に限界がありました。一方、AIによる分類は文脈分析とパターン認識技術を活用し、住所、名前、医療情報といった複雑で変化する個人情報を正確に識別することができます。
この革新的なアプローチは、以下のような利点をお客様に提供します:
- データ保護レベルの強化: 多様な個人情報タイプを正確に分類し、データ管理の複雑性を軽減しながら保護レベルを向上させます。
- 規制遵守の支援: GDPR、CCPAなどのグローバルな規制要件に対応した設計で、法的リスクを最小限に抑えます。
- 運用効率性の向上: 高速かつ正確な分類を通じて時間とコストを削減し、お客様のビジネス環境に最適化されたソリューションを提供します。
今後、QueryPieは過学習の防止、データセットの拡張、継続的な学習を通じてAIによる分類の安定性と性能をさらに向上させます。また、新しいデータ環境やお客様のニーズに迅速に対応できる柔軟なシステムを構築し、信頼性の高いサービスを提供し続けます。
さらに、QueryPieはAIDDを北米、欧州、アジア太平洋地域へ段階的にグローバル展開する計画です。各国の個人情報保護法と規制に準拠したローカライズソリューションを通じて、全世界のお客様に一貫した保護と性能を提供します。これにより、お客様はどこにいても高水準の個人情報保護と管理に対する信頼を享受できるようになります。
Appendix
参考文献
- 雇用労働部「韓国職業辞典統合版」
- 健康保険医療評価院「保健医療ビッグデータ公開システム」
- PQI(民間資格情報サービス)資格証リスト
- 住所基盤産業支援サービス韓国語住所データ
- ローマ字姓名表記規則
- 電子家族関係システム
- 国家統計ポータル
- 韓国語・英語Wikipediaダンプデータ
- Korean Naver Blogコメントデータセット
- 国立国語院「韓国語辞典」
- 国立国語院「みんなのコーパス - 新聞コーパス2022」
気になりますか?
魔法を明かしましょう!
限定コンテンツをアンロックするには、フォームにご記入ください!