개인정보 보호·관리의 新 조력자: Data Discovery
November 22, 2024
현대사회의 기업과 개인 모두 정보보호의 중요성을 인식하고 있으며, 이는 법적 규제의 강화와 함께 더욱 강조되고 있습니다. 이러한 환경 속에서 기업들은 데이터베이스에 대한 접근제어, 데이터 암호화, 조회 알람 및 기록 등 다양한 보안 조치를 통해 개인정보 보호를 강화하고 있습니다. 특히 개인정보를 다루는 서비스를 개발하는 경우, 데이터베이스의 특정 경로에 있는 개인정보를 인지하고 관리하는 것은 필수적입니다.
그러나 기업 내부에는 예상치 못한 경로를 통해 데이터가 유입될 가능성이 있으며, 이는 개인정보 보호의 범위를 더욱 넓힐 필요성을 제기합니다. 개인정보 보호법은 이름과 같이 개인을 특정할 수 있는 정보뿐만 아니라, 다른 정보와 쉽게 결합하여 개인을 식별할 수 있는 정보도 개인정보로 정의하고 있습니다. 이에 따라 기업들은 더욱 포괄적인 개인정보 관리 전략을 수립해야 합니다. 이번 블로그에서는 이러한 개인정보 보호의 중요성과 기업이 취할 수 있는 실질적인 보안 조치에 대해 깊이 있게 탐구해보겠습니다.
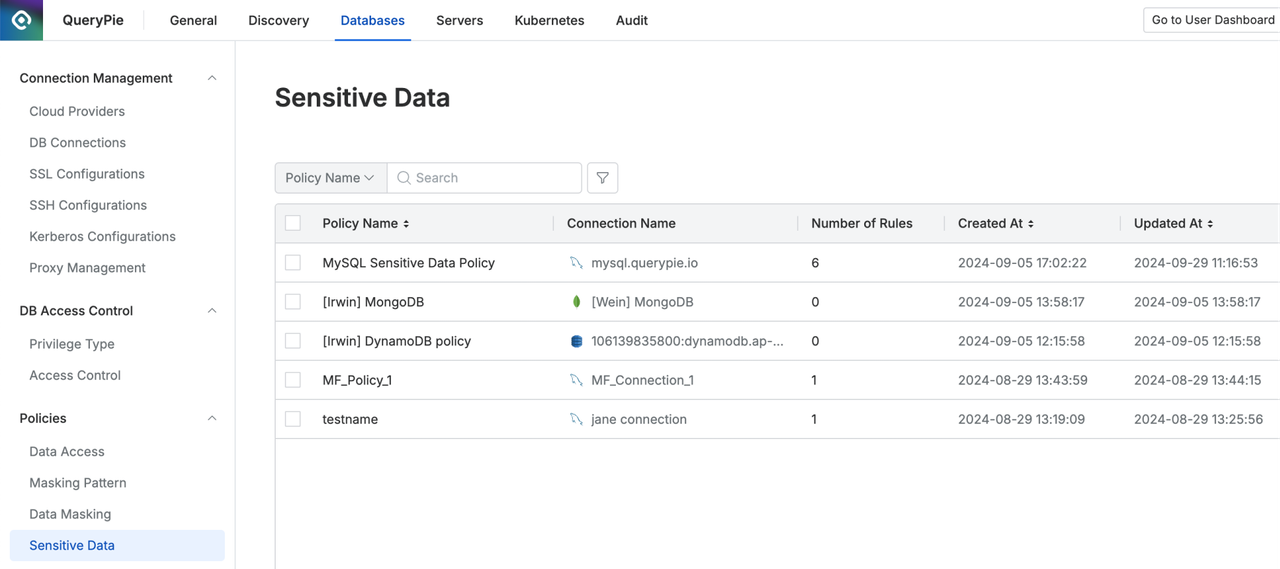
QueryPie Database 접근제어의 개인정보 정책
그렇다면, 기업 내 개인정보는 어떻게 관리되어야 할까요?
- 어디에 어떤 종류의 개인정보가 존재하는지 식별하고 분류한다.
- 사람이 수동으로 하나씩 데이터에 접근해서 조회하는 것이 아니라 자동화된 방법으로 탐색을 수행하며, 한번만 수행하는 것이 아니라 주기적, 지속적으로 수행한다.
- 발견된 개인정보에 적절한 조치(접근 제어 정책 적용, 암호화, Life cycle 관리, 마스킹, 조회 또는 변경 모니터링 등)를 한다.
Data Discovery는 위와 같은 일련의 관리 프로세스를 쉽게 처리할 수 있도록 도와줍니다.
정규식과 AI로 개인정보 식별 효율성 극대화하기
성능 좋은 무기를 병사에게 지급을 해도 적이 어디에 있는지 알 수 없다면 아무것도 할 수 없는 것 처럼, 아무리 강력한 조치방법을 가지고 있더라도 대상을 식별하지 못하면 아무것도 할 수 없습니다. 미처 알지못했던 것이 드러나는 순간 비로소 무엇을 해야할 지 결정할 수 있게 됩니다. 어떤 유형의 개인정보가 존재하는지 어떤 규제의 대상이 되는 개인정보인지 알면 적절한 대응을 할 수 있게 됩니다.
개인정보를 식별하기 위해 가장 많이 사용되는 방법이 정규식입니다. 정규식은 어떻게 만드느냐에 따라 추출범위가 상당히 차이가 나고 원하는 결과를 얻기 위해서는 상당히 복잡한 정규식이 필요할 수 있습니다. 정규식에 익숙하지 않은 관리자일 수록 복잡한 정규식을 만드는데 어려움을 겪을 수 밖에 없고 많은 시행착오를 겪게 됩니다. 만약 테스트된 복잡한 정규식을 다양하게 제공받을 수 있다면 관리자는 정규식을 새로만들기 위한 노력과 시간을 덜게 됩니다. 또는 다양한 패턴을 학습한 AI 모델을 제공받게 된다면 식별이 더욱 단순해 질 수 있습니다.
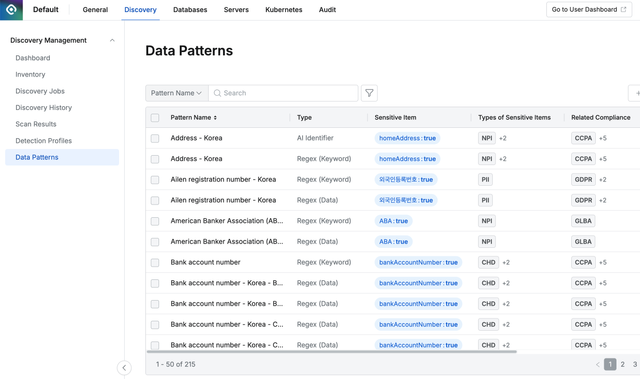
QueryPie에서 제공하는 다양한 패턴
Data Discovery 자동화: 비용 절감과 보안 강화의 길
개인정보가 특정 데이터소스에 있는지 없는지 개별적으로 접근해서 조회하는 것은 많은 시간과 노력을 필요로합니다. 한국정보보호 산업협회가 2023년 6500개 기업을 대상으로 실시한 정보보호 실태조사를 보면 정보보호 담당 인력은 평균 0.8명에 불과하다고 합니다. 그리고 대부분의 조직에서 담당자가 정보보호 담당을 전담하는 것보다 다른 일과 겸직하는 경우가 많을 것입니다. 그런 상황에서 별도 외부 컨설팅을 통해 도움을 받지 않는 한 정보보호 담당자가 조직 전체의 데이터에 대해 개인정보를 탐색하는 것은 불가능에 가까워 보입니다. 따라서 단순히 정보보호 담당자가 Data Discovery를 통해 개인정보를 탐색하도록 설정하고 스케줄을 지정해서 주기적으로 수행할 수 있도록 하는 것만으로도 기업은 추가적으로 투입되는 비용을 절감할 수 있습니다.
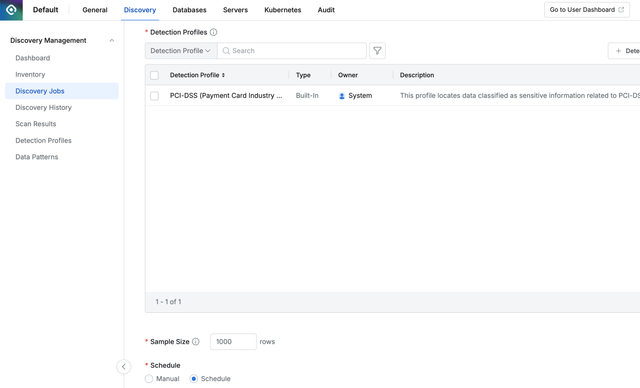
Discovery Job을 통한 쉽고 지속적인 개인정보 탐색 수행
AI와 정규식의 한계: 개인정보 식별의 현재와 미래
아무리 정교하게 작성된 정규식일지라도, 아무리 좋은 데이터로 학습된 AI 모델이라도 아직 100% 완벽하게 식별하는데는 한계가 있습니다. 앞으로 기술의 발전으로 점차 사람의 개입의 정도를 줄여나가게 되겠지만 현재로서는 식별된 결과는 필연적으로 사람의 검토가 필요합니다. 사람의 검토가 끝난 결과는 비로서 정책 적용의 대상으로 확정될 수 있습니다. 개인정보 태그는 정책 적용의 대상으로 지정되는 조건이 될 수 있습니다.
실제 QueryPie의 AIDD(AI Data Discovery)의 경우, 기업 내 데이터베이스에 존재하는 개인정보를 자동으로 식별하고 이를 효과적으로 관리할 수 있는 다양한 기능을 제공합니다. 사전 정의된 패턴과 AI 모델을 활용하여 관리자의 수고를 덜어주며, 식별된 개인정보에 태그를 부여함으로써 접근 제어 정책과의 연계를 동적으로 지원합니다. 또한, 데이터베이스의 성능에 영향을 주지 않으면서도 탐색 성능을 극대화하고, 오탐을 최소화하기 위한 지속적인 노력을 기울이고 있습니다. 이러한 기능들은 기업이 외부 규제 및 내부 정책을 준수하면서도 보안 사각지대를 최소화하는 데 기여하며, 궁극적으로는 기업의 전반적인 데이터 보호 수준을 향상시키는 데 큰 역할을 합니다. 실질적으로 기업이 데이터 보안과 개인정보 보호를 한층 강화할 수 있도록 돕는 든든한 조력자 역할을 수행하는 셈입니다.
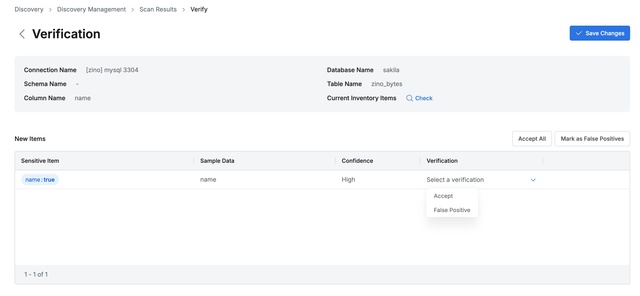
식별된 결과에 대한 검토
결론적으로
데이터 디스커버리를 통해 기업은 단순한 접근 제어 정책만으로는 놓치기 쉬운 보안 사각지대를 효과적으로 관리할 수 있습니다. 이를 통해 기업은 데이터 보호 수준을 한층 높일 수 있으며, 정보보호 규정 및 내부 정책에 부합하는 대응 방안을 마련할 수 있습니다. 기업의 개인정보 관리의 새로운 조력자로 떠오르는 데이터 디스커버리를 통해 앞으로 더 많은 기업들이 철저한 데이터 보호를 실현할 수 있을 것 입니다.